 L'article de Nikita Prokopov à lire absolument à propos de l'UTF-8.
L'article de Nikita Prokopov à lire absolument à propos de l'UTF-8.
Cet article est une traduction en français de l'article suivant : https://tonsky.me/blog/unicode/. Tous les droits vont à Nikita Prokopov.
Il y a vingt ans, Joel Spolsky écrivait:
Le Texte Brut (Plain Text en anglais), ça n'existe pas.
Cela n'a aucun sens d'avoir une chaîne de caractères sans savoir quel encodage est utilisé. Vous ne pouvez pas continuer à vous mettre la tête dans le sable et prétendre que du texte "brut" est de l'ASCII.
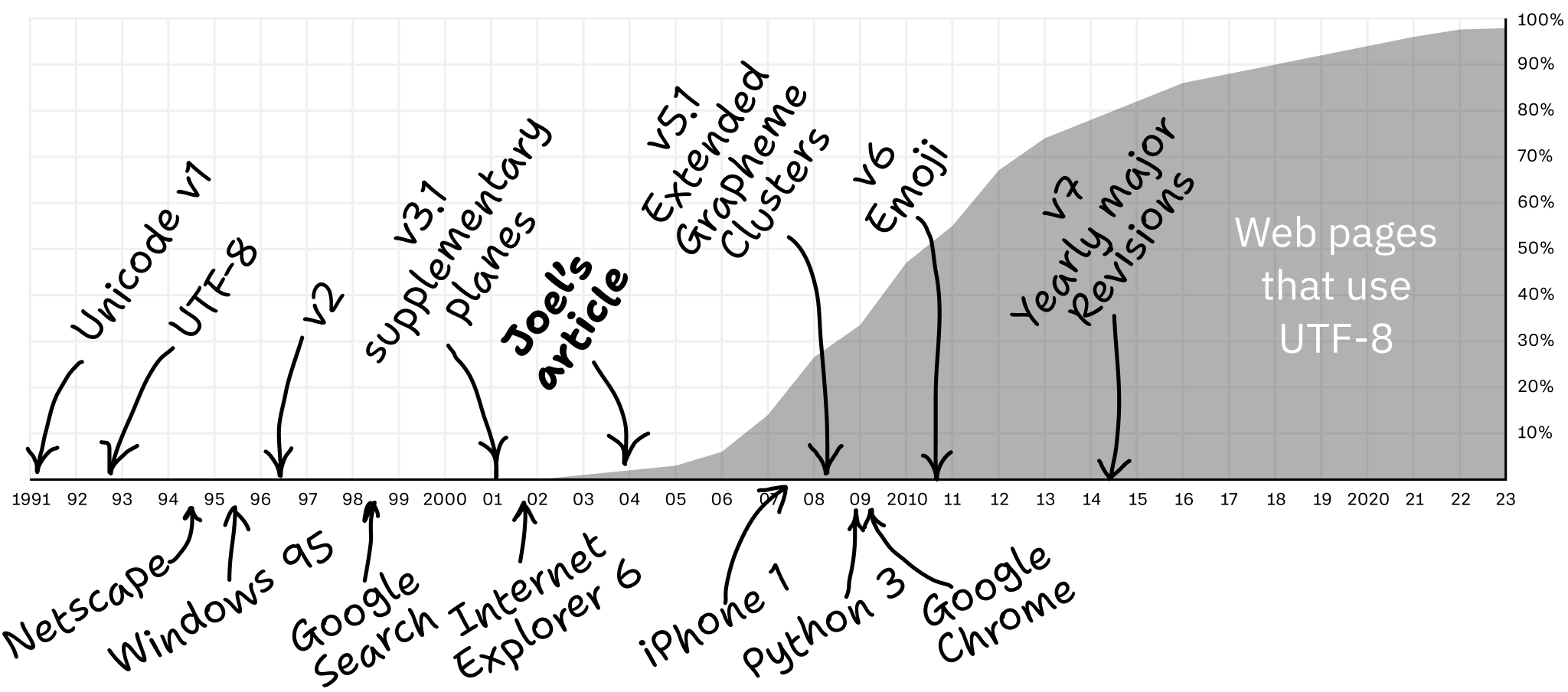
Beaucoup de choses ont changé en 20 ans. En 2003, la question principale était : quel est l'encodage de ce truc ?
En 2023, la question n'a plus lieu d'être : à 98% de probabilité, c'est de l'UTF-8. Enfin ! On peut à nouveau se mettre la tête dans le sable !
La question devient donc maintenant : comment utiliser l'UTF-8 correctement ? Voyons ça !
L'Unicode est un standard qui vise à unifier tous les langages humains, passés comme présents, et à les faire fonctionner sur les ordinateurs.
En pratique, l'Unicode est une table qui attribue un nombre unique à chaque caractère différent.
Par exemple :
A est attribué le nombre 65.س vaut 1587.ツ vaut 12484𝄞 vaut 119070.💩 vaut 128169.L'Unicode fait référence à ces nombres en tant que points-codes (code points en anglais).
Puisque la terre entière s'accorde sur l'attribution de tels nombres à tels caractères, et que la terre entière utilise l'Unicode, chacun peut lire les textes des autres.
Unicode == caractère ⟷ point-code.
Actuellement, le point-code défini le plus élevé vaut 0x10FFFF. Ce qui donne un espace d'environ 1,1 million de points-codes.
Environ 170 000 points, soit 15%, sont actuellement définis. 11% de plus sont réservés à un usage privé. Le reste, autour de 800 000 points-codes, ne sont pour l'instant pas alloués. Ils pourraient devenir des caractères dans le futur.
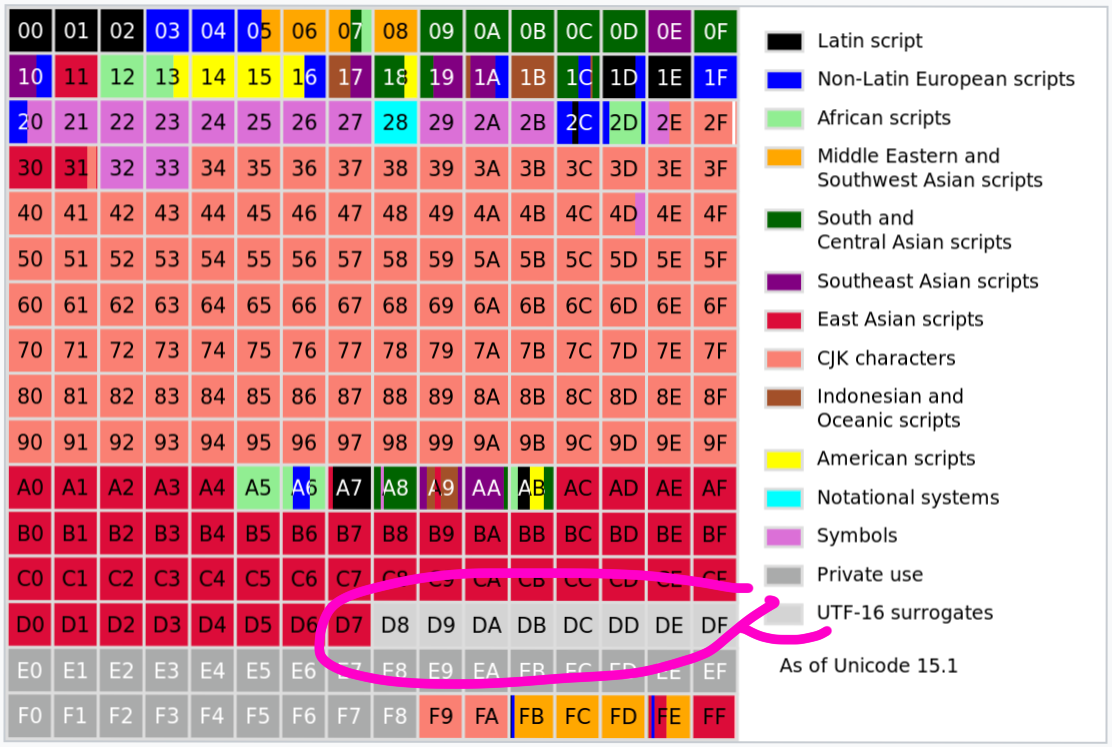
Voici globalement à quoi ça ressemble :
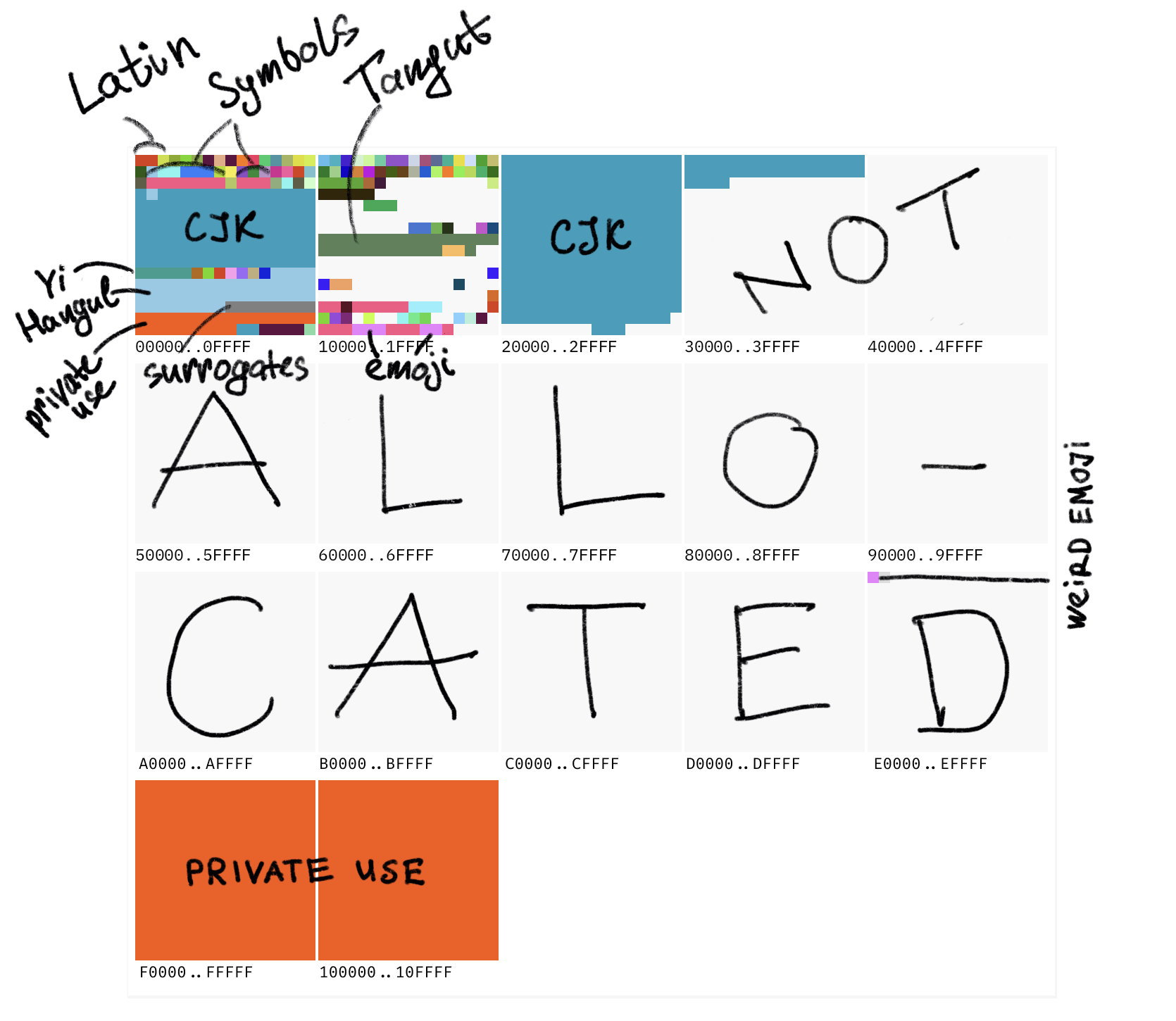
Grand carré == plan == 65 536 caractères. Petit carré == 256 caractères. L'intégralité de l'ASCII se trouve dans la moitié du petit carré rouge en haut à gauche.
Certains points-codes sont réservés pour les développeurs d'application et ne seront jamais définis par l'Unicode en tant que tel.
Par exemple, il n'y a aucune place pour le logo d'Apple dans l'Unicode, Apple l'a donc inséré en U+F8FF qui se trouve dans le bloc d'Usage Privé. Dans une autre police de caractères, il sera rendu comme un glyphe manquant , mais dans la police intégrée à macOS, vous verrez ![]() .
.
La Zone d'Usage Privé est principalement utilisée pour les polices d'icônes :
U+1F4A9 signifie ?Il s'agit d'une convention sur la façon d'écrire les valeurs des points-codes. Le préfixe U+ signifie, ben, Unicode, et 1F4A9 est la valeur du point-code en hexadécimal.
Ah, et U+1F4A9 en particulier est 💩.
L'UTF-8 est un encodage. L'encodage est la technique de stockage des points-codes en mémoire.
L'encodage le plus simple pour l'Unicode est l'UTF-32. Il stocke chaque point-code sur un entier de 32 bits. Par conséquent, U+1F4A9 devient 00 01 F4 A9, occupant quatre octets. Tous les points-codes occupent également quatre octets. Puisque que le point-code le plus élevé vaut U+10FFFF, il est garanti que toutes les valeurs vont tenir (dans 4 octets NdT).
L'UTF-16 et l'UTF-8 sont moins directs, mais le but final reste le même : prendre un point-code et l'encoder sous forme d'octets.
L'encodage est actuellement ce à quoi vous être confronté en tant que programmeur.
L'UTF-8 est un encodage à longueur variable. Un point-code peut être encodé comme une séquence de un à quatre octets.
Voilà comment ça fonctionne :
| point-code | Octet 1 | Octet 2 | Octet 3 | Octet 4 |
|---|---|---|---|---|
U+0000..007F |
0xxxxxxx |
|||
U+0080..07FF |
110xxxxx |
10xxxxxx |
||
U+0800..FFFF |
1110xxxx |
10xxxxxx |
10xxxxxx |
|
U+10000..10FFFF |
11110xxx |
10xxxxxx |
10xxxxxx |
10xxxxxx |
Si vous combinez ça avec la table de l'Unicode, vous verrez que l'Anglais est encodé avec un octet, le Cyrillique, les langages latins d'Europe, l'Hébreu et l'Arabe en demandent 2 ; et le Chinois, le Japonais, le Coréen et les autres langages asiatiques ainsi que les Emojis en demandent 3 ou 4.
Quelques remarques importantes :
Premièrement, l'UTF-8 est compatible au niveau octet (byte-compatible en anglais) avec l'ASCII. Les points-codes 0..127, l'ancien ASCII, sont encodés sur un octet avec exactement les mêmes valeurs. U+0041 (A, Lettre Latine Capitale A) est simplement 41, un octet.
Tout texte en simple ASCII est également un texte valide en UTF-8, et tout text en UTF-8 n'utilisant que les points-codes 0..127 peut être directement lu comme de l'ASCII.
Deuxièmement, l'UTF-8 est peu encombrant (space-efficient en anglais) pour le Latin de base. Cela était un de ses arguments de vente par rapport à l'UTF-16. Ce n'est peut-être pas très juste pour les textes du monde entier, mais pour les chaînes techniques telles que les balises HTML ou les clés JSON, ça a tout son sens.
En moyenne, l'UTF-8 devient plutôt un bon plan, même pour les ordinateurs non-Anglais. Et pour l'Anglais, c'est juste imbattable.
Troisièmement, l'UTF-8 offre une détection et une récupération d'erreur embarquées (built-in en anglais). Le préfixe du premier octet apparait toujours différent des octets 2-4. De cette façon vous pouvez toujours dire si ce que vous regardez est une séquence complète et valide d'octets UTF-8 ou s'il manque quelque chose (par exemple, si vous avez sauté au milieu d'une séquence). Vous pouvez alors corriger en vous déplaçant en avant ou en arrière jusqu'à trouver le début de la séquence correcte.
Et quelques conséquences importantes :
Si vous le faites, vous pourriez bien rencontrer ce mauvais garçon : �
U+FFFD, le Caractère de Remplacement, est simplement un autre point-code dans la table Unicode. Les applications et les librairies peuvent l'utiliser en cas de détection d'erreurs Unicode.
Si vous supprimez la moitié d'un point-code, il n'y a pas grand chose à faire de l'autre moitié en dehors d'afficher une erreur. C'est là que � est utilisé.
var bytes = "Аналитика".getBytes("UTF-8");
var partial = Arrays.copyOfRange(bytes, 0, 11);
new String(partial, "UTF-8"); // => "Анал�"NON.
L'UTF-32 est super pour travailler sur les points-codes. En effet, si chaque point-code est toujours sur 4 octets, alors strlen(s) == sizeof(s) / 4, substring(0, 3) == bytes[0, 12], etc.
Le problème est que vous ne voulez pas travailler sur les points-codes. Un point-code est une unité d'écriture ; un point-code n'est pas toujours un caractère unique. Ce sur quoi vous devriez itérer sont appelés des “groupes de graphèmes étendus” (“extended grapheme clusters” en anglais), ou graphèmes en bref.
Un graphème est une unité distinctive minimale d'écriture dans le contexte d'un système d'écriture particulier. ö est un graphème. é également. Et 각. De base, un graphème est ce à quoi pense l'utilisateur lorsqu'il pense à un caractère unique.
Le problème étant que, en Unicode, certains graphèmes sont encodés sur plusieurs points-codes !

Par exemple, é (un graphème unique) est encodé en Unicode comme e (U+0065 La Lettre Latine Minuscule E) + ´ (U+0301 Accent Aigu Combiné). Deux points-codes !
Il peut y en avoir plus de deux :
☹️ is U+2639 + U+FE0F👨🏭 is U+1F468 + U+200D + U+1F3ED🚵🏻♀️ is U+1F6B5 + U+1F3FB + U+200D + U+2640 + U+FE0Fy̖̠͍̘͇͗̏̽̎͞ is U+0079 + U+0316 + U+0320 + U+034D + U+0318 + U+0347 + U+0357 + U+030F + U+033D + U+030E + U+035EAutant que je sache, il n'y a pas de limite.
Souvenez-vous, nous sommes en train de parler de points-codes. Même dans le système d'encodage le plus large, l'UTF-32, 👨🏭 demandera trois unités de 4 octets pour être encodé. Et doit toujours être considéré comme un seul caractère (plutôt graphème NdT).
Si l'analogie peut être utile, nous pouvons imaginer que l'Unicode en tant que tel (sans encodings) est de longueur variable (variable-length en anglais).
Un Groupe de Graphèmes Étendu est une séquence d'un ou plusieurs points-codes Unicode qui doivent être traités comme un caractère unique et insécable. |
Par conséquent, nous retrouvons tous les problèmes des encodages à longueur variable, mais au niveau des points-codes : vous ne pouvez pas prendre seulement une partie de la séquence, elle doit toujours être sélectionnée, copiée, éditée ou effacée dans son entièreté.
Le non-respect des groupes de graphèmes provoque des bogues comme celui-ci :
ou celui-là :
Utiliser l'UTF-32 au lieu de l'UTF-8 ne vous facilitera pas la vie par rapport aux groupes de graphèmes étendus. Et les groupes de graphèmes étendus sont ce à quoi il faut prêter attention.
Points-codes — 🥱. Graphèmes — 😍 |
Pas vraiment. Les Groupes de Graphèmes Étendus sont aussi utilisée dans des langues vivantes et fréquemment utilisées. Par exemple :
ö (Allemand) est un caractère unique, mais plusieurs points-codes (U+006F U+0308).ą́ (Lituanien) vaut U+00E1 U+0328.각 (Coréen) vaut U+1100 U+1161 U+11A8.Donc non, ce n'est pas seulement pour les emojis.
Question inspirée de ce brillant article (en anglais).
Des langages de programmation différents donneront joyeusement des réponses différentes.
Python 3:
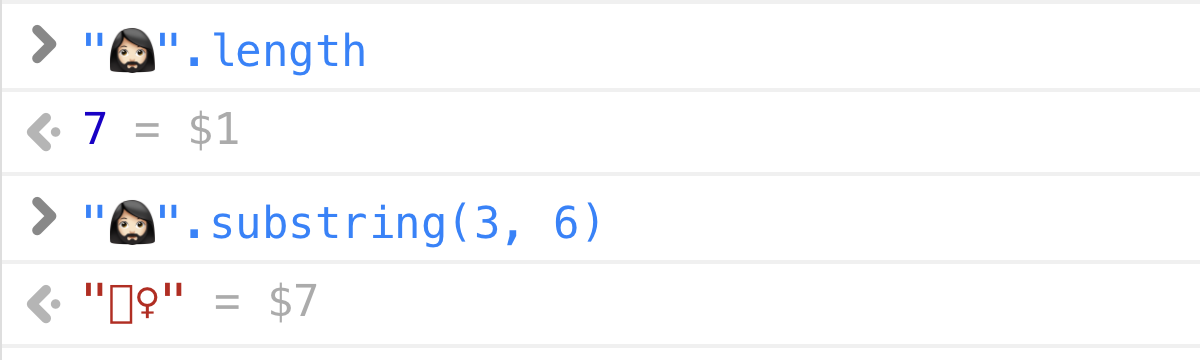
>>> len("🤦🏼♂️")
5JavaScript / Java / C#:
>> "🤦🏼♂️".length
7Rust:
println!("{}", "🤦🏼♂️".len());
// => 17Comme vous l'avez peut-être deviné, les différents langages utilisent dans leur mécanique interne des représentations des chaînes de caractères differentes (UTF-32, UTF-16, UTF-8) et renvoient des longueurs en rapport avec l'unité utilisée pour stocker les caractères (entiers, courts, octets ; ints, shorts, bytes en anglais).
MAIS ! Si vous demandez à une personne normale, quelqu'un qui n'est pas accablé par la mécanique interne de l'informatique, elle vous donnera une réponse directe : 1. La longueur de la chaîne 🤦🏼♂️ est 1.
C'est la raison d'être des groupes de graphèmes étendus : qu'est-ce que les humains perçoivent comme un caractère unique. Et dans ce cas, 🤦🏼♂️ est sans aucun doute un caractère unique.
Le fait que 🤦🏼♂️ soit constitué de 5 points-codes (U+1F926 U+1F3FB U+200D U+2642 U+FE0F) est un détail de pure implémentation. Il ne devrait pas être cassé en morceaux, il ne devrait pas être comptabilisé comme plusieurs caractères, il ne devrait pas pouvoir être partiellement sélectionné, le curseur ne devrait pas pouvoir être positionné au milieu, etc.
À toute fin utile, il s'agit d'une unité atomique de texte. En interne, elle peut être encodée de n'importe quelle manière, mais pour l'API orientée utilisateur, elle doit être traitée comme un tout.
Le seul langage moderne à retourner la bonne valeur est Swift :
print("🤦🏼♂️".count)
// => 1Basiquement, il existe deux couches :
.count or .substring. Swift vous donne une vue (view en anglais) qui prétend que la chaîne est une séquence de groupes de graphèmes. Et cette vue se comporte comme un humain s'y attendrait : elle renvoie 1 pour "🤦🏼♂️".count.J'espère que d'autres langages vont rapidement adopter cette conception.
Question au lecteur : d'après vous, qu'elle devrait-être la valeur de "ẇ͓̞͒͟͡ǫ̠̠̉̏͠͡ͅr̬̺͚̍͛̔͒͢d̠͎̗̳͇͆̋̊͂͐".length ?
Malheureusement, la plupart des langages choissisent la méthode facile et vous permettent d'itérer à travers les chaînesd de caractères par blocs de 1-2-4 octets, mais pas par groupes de graphèmes.
Cela n'a aucun sens et aucune sémantique, mais puisqu'il s'agit du comportement par défaut, les programmeurs n'y réfléchissent pas deux fois, et les résultats obtenus sont des chaînes corrompues :
“Je sais, je vais utiliser une librairie pour utiliser strlen() !” — jamais personne.
Mais c'est exactement ce que vous devriez faire ! Utiliser une librairie Unicode adéquaté ! Oui, pour des choses aussi simples que strlen ou indexOf ou substring !
Par exemple :
TextElementEnumerator, qui est maintenu à jour avec Unicode pour autant que je sache.Mais quelque soit votre choix,, assurez-vous d'utiliser une version suffisamment récente d'Unicode (15.1 lors de la rédaction de cet article), car la définition des graphèmes change d'une version à l'autre. Par exemple, java.text.BreakIterator en Java est un no-go: il est basé sur une vieille version d'Unicode est n'est pas mis à jour.
Utiliser une librairie |
A mon avis, la situation est globalement honteuse. L'Unicode devrait se trouver par défaut dans la stdlib de tout langage. C'est la lingua franca d'Internet ! Et ce n'est pas nouveau : nous vivons avec l'Unicode depuis maintenant 20 ans.
Oui ! C'est pas trop cool ?
(Je sais, c'est pas cool du tout)
A partir de 2014 environ, Unicode a commencé à publier une révision majeur de leur standard chaque année. C'est comme ça que vous obtenez vos nouveaux emojis — les mises à jour Android et iOS de l'automne incluent généralement le dernier standard Unicode entre autre.
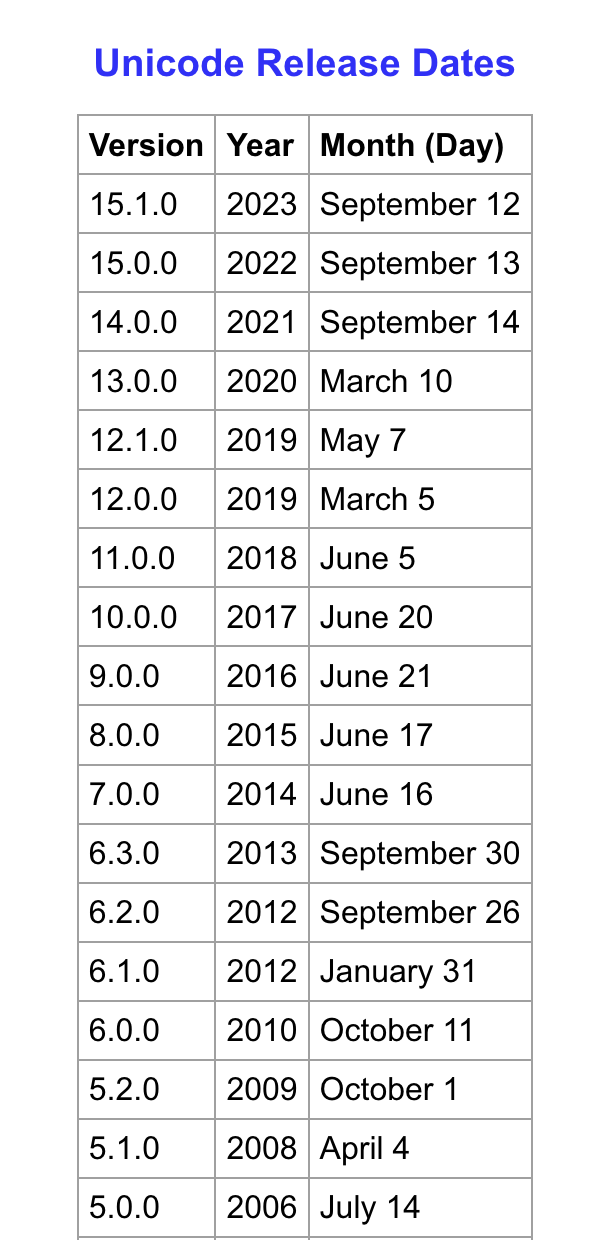
Ce qui est triste pour nous c'est que les règles définissant les groupes de graphèmes changent aussi chaque année. Ce qui est considéré comme une séquence de deux ou trois points-codes séparés aujourd'hui peut devenir un groupe de graphèmes demain ! Il n'y aucun moyen de savoir ! Ni de s'y préparer !
Encore pire, les différentes versions de votre propre application peut tourner sur différente version du standard Unicode et renvoyer des longueurs de chaînes de caractères différentes !
Mais c'est la réalité à laquelle nous sommes confrontés. Vous n'avez pas vraiment le choix dans le cas présent. Vous ne pouvez pas ignorer l'Unicode ou ses mises à jour si vous voulez rester pertinent et fournir une expérience utilisateur acceptable. Alors, attachez votre ceinture, faites-en votre partie et mettez à jour.
Mettre à jour tous les ans |

Copiez et collez ces lignes dans votre console JavaScript :
"Å" === "Å"
"Å" === "Å"
"Å" === "Å"Qu'est-ce que vous obtenez ? False ? Vous devriez obtenir faux (false), et ce n'est pas une erreur.
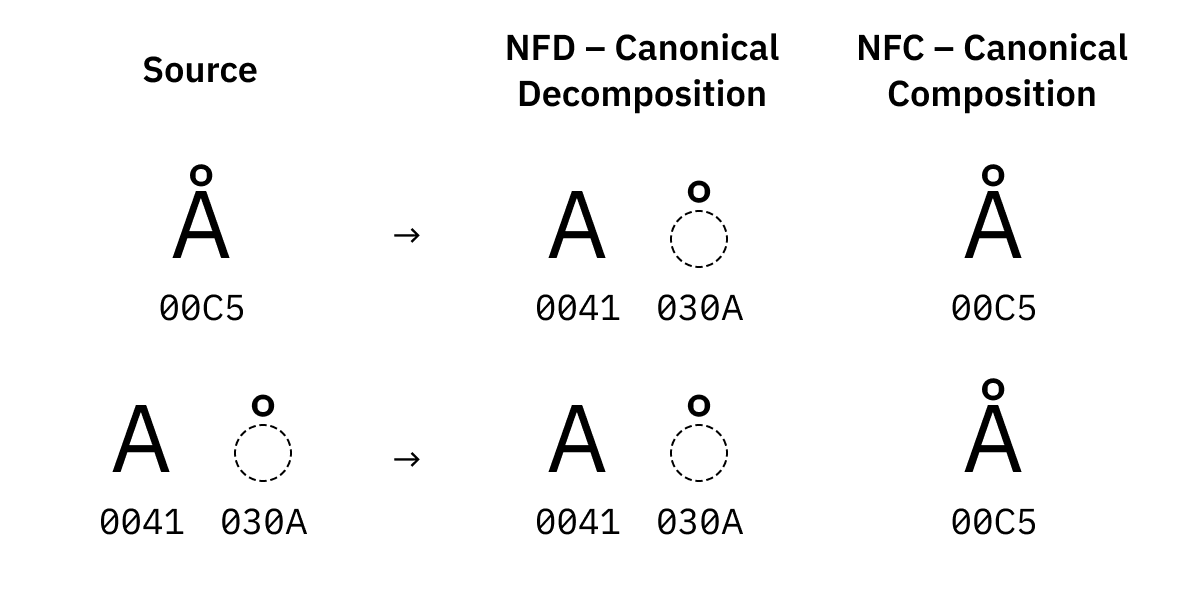
Vous vous souvenez lorsque j'expliquais que ö est constitué de deux points-codes, U+006F U+0308 ? Basiquement, l'Unicode offre plus d'une méthode pour écrire des caractères comme ö ou Å. You pouvez :
Å à partir du Latin A normal + un caractère combinant,U+00C5 qui le fait pour vous.Ils sembleront identiques (Å vs Å), ils devraient fonctionner de manière identique, et à toute fin utile, ils sont considérés comme strictement identiques. La seule différence est la représentation octale.
Voilà pourquoi nous avons besoin de normalisation. Il en existe quatre formes :
NFD tente d'éclater en morceaux aussi petits que possible, et trie également les morceaux dans un ordre canonique s'il y en a plusieurs.
NFC, à l'inverse, essaie de tout combiner sous des formes pré-composées lorsqu'elles existent.
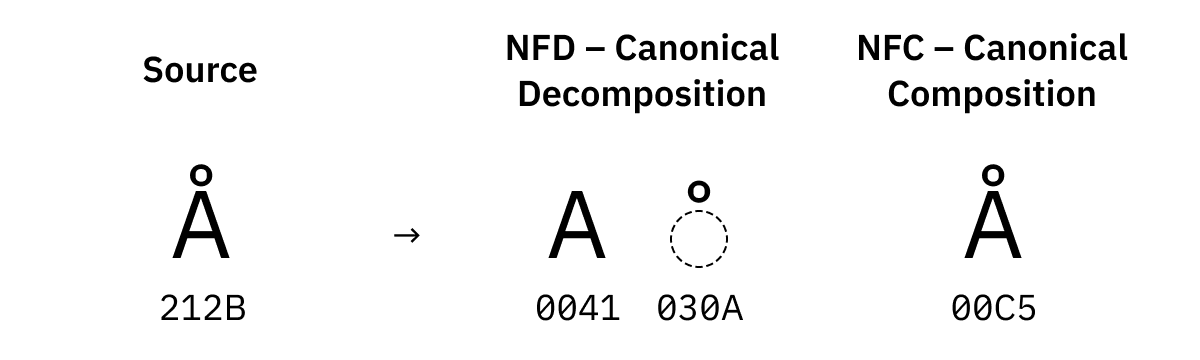
Pour certaines caractères il existe également plusieurs versions dans l'Unicode. Par exemple, il y a U+00C5 Latin Capital Letter A with Ring Above, mais il y a aussi U+212B Angstrom Sign qui semble identique.
Ils sont également remplacés durant la normalisation :
NFD and NFC sont appelés des "normalisations canoniques”. Les deux autres formessont des "normalisations de compatibilité" :
NFKD tente de tout éclater et de remplacer les variantes visuelles par les versions par défaut.
NFKC tente de tout combiner en remplaçant les variantes visuelles par les versions par défaut.
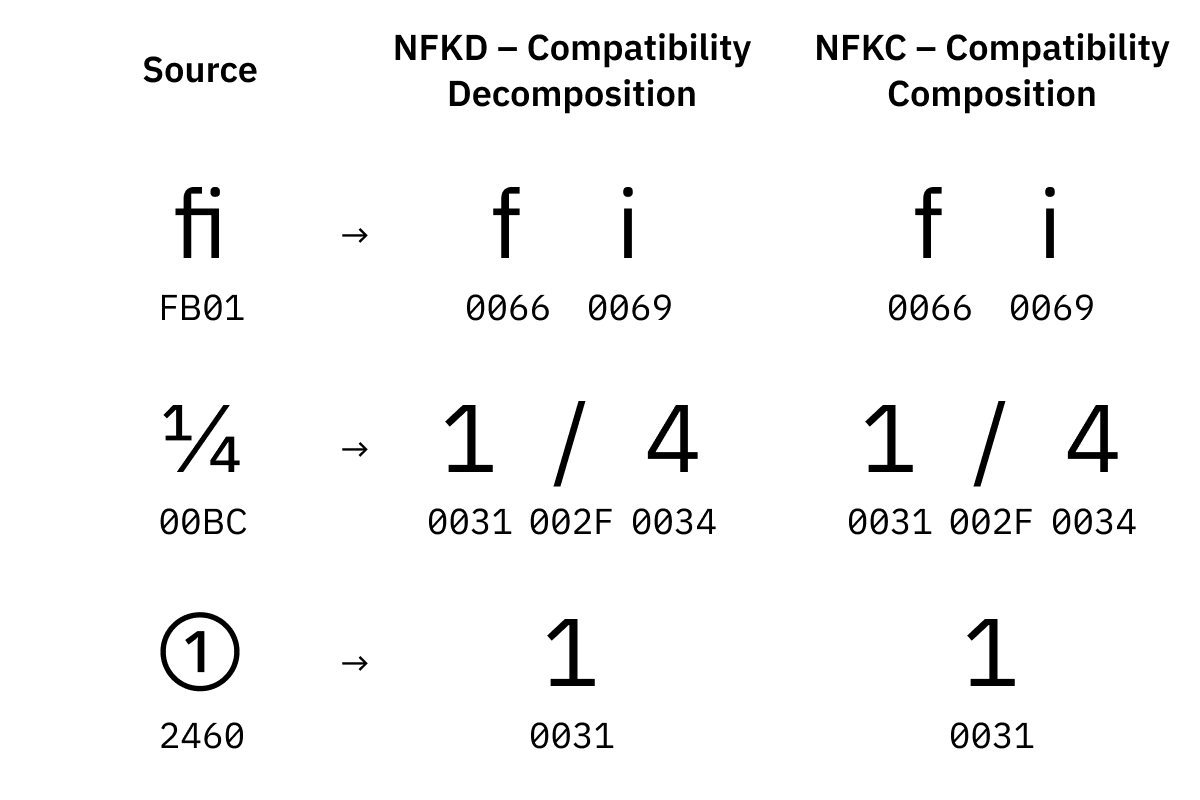
Les variantes visuelles sont des points-codes Unicode qui représentent le même caractère mais sont supposées en faire un rendu différent. Comme ① ou ⁹ ou 𝕏. On veut être capable de trouver aussi bien "x" et "2" dans une chaîne de caractère comme "𝕏²", n'est-ce pas ?

Pourquoi même la ligature fi a-t-elle sont propre point-code ? Aucune idée. Il peut se passer beaucoup de choses dans un million de caractères.
Avant de manipuler des chaînes de caractères ou de chercher une sous-chaîne, normaliser ! |
Le nom russe Nikolay s'écrit comme cela :
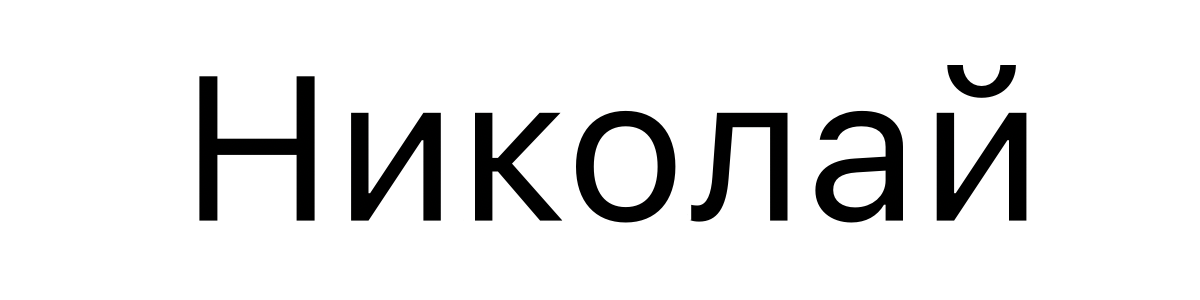
et est encodé en Unicode par U+041D 0438 043A 043E 043B 0430 0439.
The nom bulgare Nikolay s'écrit :
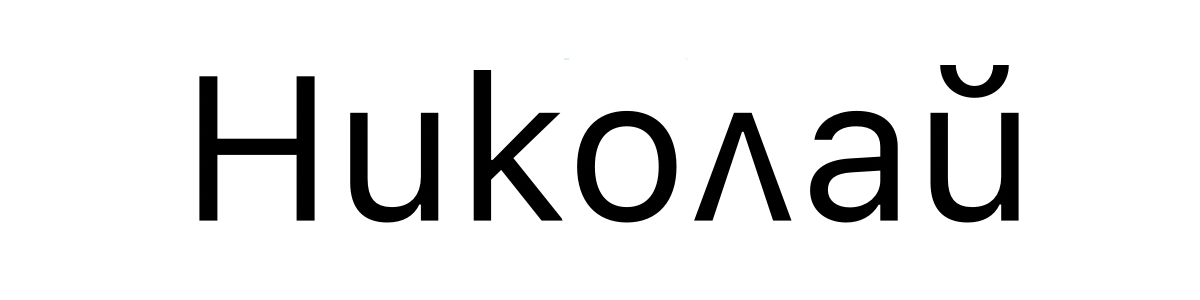
et est encodé en Unicode par U+041D 0438 043A 043E 043B 0430 0439. Exactement la même chose !
Attendez une seconde! Comment l'ordinateur sait-il qu'il doit afficher les glyphes bulgares ou les glyphes russes ?
Réponse courte : il n'en sait rien. Malheureusement, l'Unicode n'est pas un système parfait, et il comporte de nombreuses lacunes. En autre, assigner le même point-code à des glyphes qui sont supposés avoir une graphie différente, comme le K mininuscule cyrillique et le K minuscule bulgare (les deux valant U+043A).
De ce que j'en comprends, c'est bien pire pour les asiatiques : de nombreux logogrammes chinois, japonais et coréens sont écrit différemment mais se voient assigner le même point-code :

La motivation d'Unicode est d'économiser de l'espace pour les points-code (supposition personnelle). L'information sur comment le rendu doit être assuré est supposé être transféré en dehors de la chaîne de caractères, en tant que métadonnées régionales/linguistiques.
Malheureusement, cela va à l'encontre de l'objectif initial de l'Unicode :
[...] aucune séquence d'échappement ou code de contrôle n'est nécessaire pour spécifier n'importe quel caractère dans n'importe quelle langue.
En pratique, la dépendance régionale crée plusieurs soucis :
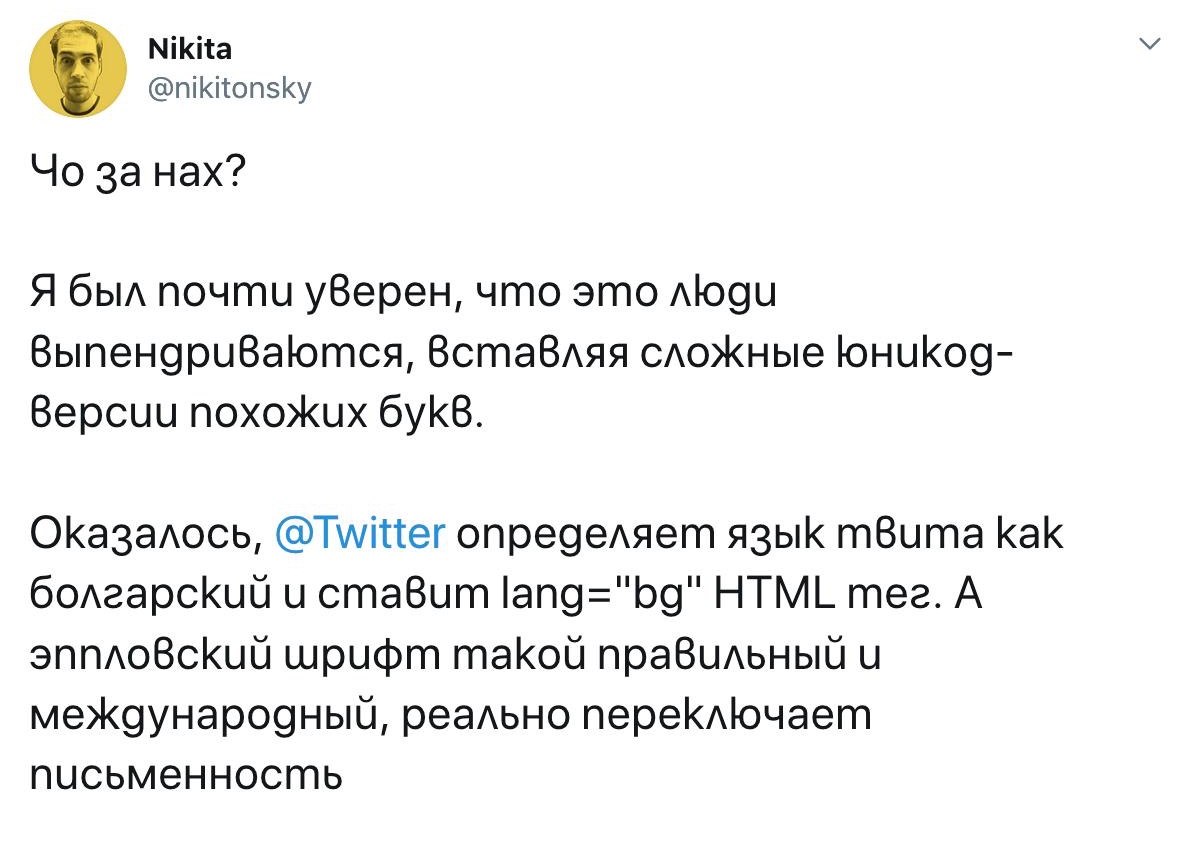
String::toLowerCase() accepte-t-elle Locale en argument ?Un autre exemple malencontreux de la dépendance au paramètre régional est la gestion par Unicode du i sans point dans la langue turque.
Contrairement aux anglais (ou aux français NdT), les turques ont deux variantes de I : avec ou sans point. L'Unicode a décidé de réutiliser I et i de l'ASCII et d'ajouter seulement deux nouveaux points-codes : İ et ı.
Malheureusement, cela provoque un comportement différent de toLowerCase/toUpperCase pour la même valeur d'entrée :
var en_US = Locale.of("en", "US");
var tr = Locale.of("tr");
"I".toLowerCase(en_US); // => "i"
"I".toLowerCase(tr); // => "ı"
"i".toUpperCase(en_US); // => "I"
"i".toUpperCase(tr); // => "İ"Donc non, vous ne pouvez pas convertir des chaînes de caractères en minuscules sans savoir dans quelle langue elles sont été écrites.

“ ” ‘ ’,’,– —,• ■ ☞,$ (ça donne comme un indice sur qui a inventé les ordinateurs, non ?): € ¢ £,+ et égal = font partie de l'ASCII, mais moins − et multiplier × non ¯\_(ツ)_/¯,© ™ ¶ † §.Enfer et damnation, vous ne pouvez même pas épeler café, piñata ou naïf sans l'Unicode. Donc, oui, nous sommes tous dans le même bateau, mêmes les Ricains.
Touché (en français dans le texte).
Cela remonte à la v1 d'Unicode. La première version d'Unicode était supposée être basée sur une longueur fixe. Une longueur fixe de 16-bit pour êter précis :

Ils pensaient que 65 536 caractères seraient suffisants pour toutes les langages humains. Ils y étaient presque !
Lorsqu'ils ont compris qu'il leur faudrait plus de points-codes, UCS-2 (une version originale de l'UTF-16 sans substituts) était déjà utilisé par de nombreux systèmes. 16 bit, longueur fixe, cela ne vous donne que 65 536 characters. Que faire ?
Unicode décida d'utiliser certains de ces 65 536 caractères pour encoder les points-codes de valeurs plus élevées, essentiellement en convertissant UCS-2 de longueur fixe en l'UTF-16 de longueur variable.
Une paire de substitution est composée de deux unités UTF-16 utilisées pour encoder un unique point-code Unicode. Par exemple, D83D DCA9 (deux unités de 16 bits) encode un point-code, U+1F4A9.
Les 6 premiers bits des paires de substitution sont utilisés comme masque, laissant 2×10 bits libres à exploiter :
High Surrogate Low Surrogate
D800 ++ DC00
1101 10?? ???? ???? ++ 1101 11?? ???? ????Techniquement, chaque moitié de la pair de substitution peut être considéré comme un point-code, aussi. En pratique, toute la plage allant de U+D800 à U+DFFF est réservée “uniquement pour les paires de substitution”. Les points-codes de cette plage ne sont même pas considérés comme valides dans les autres encodages.
Oui !
La promesse d'un encodage sur longueur fixe qui couvre l'ensemble des langages humains étaient si convaincante que de nombreux systèmes ses sont empressés de l'adopter. Parmi lesquels Microsoft Windows, Objective-C, Java, JavaScript, .NET, Python 2, QT, SMS, et CD-ROM !
Depuis, Python a évolué, le CD-ROM est devenu obsolète, mais les autres sont bloqués avec UTF-16 ou même UCS-2. Donc l'UTF-16 est encore vivant comme représentation en mémoire.
En termes pratiques, aujourd'hui, l'UTF-16 offre à peu près la même facilité d'utilisation que l'UTF-8. Il est également base sur une longueur variable ; dénombrer les unités UTF-16 est aussi inutile que des comptes les octets ou les points-codes, les groupes de graphèmes sont toujours une plaie, etc. La seule différence réside dans la quantité de mémoire requise.
Le seul inconvénient de l'UTF-16 c'est que tout le reste est en UTF-8, cela demande donc une conversion à chaque fois qu'une chaîne de caractères est lue depuis le réseau ou le disque.
Autre anecdote amusante : le nombre de plans Unicode (17) est défini par le nombre de pairs de substitution exprimable en UTF-16.
Pour résumer :
strlen, indexOf et substring.Globalement, c'est vrai, l'Unicode n'est pas parfait, mais il faut bien dire que
c'est un miracle. Envoyez ça à tous vos collègues développeurs afin qu'il puisse le savoir aussi.
Le texte brut, ça existe, et c'est encodé en UTF-8. |
Merci à Lev Walkin et à mes mécènes pour les lectures des brouillons de cet article.
Lien : Article original (en anglais)